
원시 자료형과 참조 자료형
원시 자료형 (primitive type data)

객체가 아니면서 메서드(method)를 가지지 않는 Boolean, String, Number, Null, undefined, Symbol 이 해당된다. 이 값은 메모리영역 내에서 하나의 값을 담는 스택(stack)에 각각 저장되며, 변수의 이름을 통해 스택에서 호출해 값을 사용 할 수 있다.
왜 “원시” 자료형일까?

원시 자료형은 모두 하나의 데이터를 담고 있다. 과거에는 데이터 저장소의 용량이 제한되어 변수 하나에 데이터 용량이 제한된 하나의 원시형 자료를 담을 수밖에 없었다.
사진에서 쓰이는 언어는 옛날 컴퓨터에 사용되던 BASIC이라는 컴퓨터 언어이다. string과 number는 쉽게 확인 할 수 있지만 배열에 상응하는 데이터는 찾기 어렵다. 스택에 하나의 데이터만 넣을 수 있는 “원시적인” 방식이다.
변수에는 하나의 데이터만 담는다
const num1 = 123;
const num2 = 123456789;
"hello world!"
"hello codestates!"
// "hello world!" 와 "hello codestates!"는 모두 변경할 수 없는 고정된 값
let word = "hello world!"
word = "hello codestates!"
// word라는 변수에 재할당을 하여 변수에 담긴 내용을 변경하는 것은 가능
const num1 = 123;
num1 = 123456789; // 에러 발생
// const 키워드로 선언하면 재할당은 불가원시 자료형의 보관함(스택)인 변수에는 하나의 원시 자료형만 담을 수 있다. 코드 작성에 따라 보관되는 데이터가 천 개, 만 개가 될 수도 있는 참조 자료형과 달리 원시 자료형은 “하나”의 의미를 가지는 데이터이기 때문에 원시 자료형이 담기는 보관함의 크기는 고정하는 것이 합당하다. 어느정도 일정한 크기의 데이터가 온다고 예상 할 수 있기 때문이다.

원시 자료형은 값 자체에 대한 변경이 불가능(immutable)하지만, 변수에 다른 데이터를 할당하는 것은 가능하다. 원시 타입 데이터를 복사할 경우, 데이터 값이 복사되기 때문에 기존 데이터에 영향이 가지 않는다.
참조 자료형 (reference data type)
원시 자료형이 아닌 모든 것은 참조 자료형이며 배열(Array), 객체(Object), 함수(Function) 가 대표적이다. 과거엔 배열, 즉 리스트라는 개념을 구현하기 어려웠기 때문에 띄어쓰기, 탭, 쉼표 등으로 데이터를 구분하여 배열과 비슷한 형태로 자료 구조를 구현하기 시작했다. 이는 쉼표로 구분된 데이터라는 의미를 가진 csv(comma-separated values)에서도 찾아볼 수 있다.
이제 대부분의 컴퓨터 언어에는 JavaScript처럼 배열(혹은 유사한)이라는 자료 구조가 구현되어 있으며 요소의 추가, 삭제, 변경 정도만 알고 있다면 쉽게 배열을 다룰 수 있다. 따로 자료 구조를 구현한 이유는 변수에 넣을 수 있는 데이터 크기가 제한되기 때문이다.

배열을 예로 들어 생각했을 때, 스택에 값을 저장한다고 생각해보자. 하나의 이름에 여러 값을 담고 수정해야 하기 때문에 많은 저장소를 사용하게 되고, 배열이 많아지고 수정이 되기 시작하면 이름과 값을 찾아 사용하는데에 많은 시간과 코스트가 소모되기 때문에 비효율적이다.
참조 자료형이 저장되는 특별한 데이터 저장소, 힙(heap)

그래서 메모리 공간에는 힙(heap) 이라는 별도의 공간이 존재하며 이 곳에서는 스택과 달리 하나의 값이 아닌 다양한 값을 동적(dynamic)으로 담을 수 있다. 스택에는 이름과 힙의 주소만 저장되며 호출이 되면 힙에서 주소를 찾아 반환한다. 데이터는 별도로 관리되고 주소를 참조(reference)하기 때문에 참조 자료형이라 일컫는다.
100만 개의 데이터가 들어올 수 있는 상황이라면 고정된 데이터 공간을 사용하는 것 보다 크기가 상황에 따라 동적으로 변하는 특별한 데이터 저장소를 사용하는 것이 합당하다. 때문에 언제 늘어나고 줄어들지 모르는 데이터는 별도의 저장 공간을 마련하여 따로 관리하기로 합의되었다.
배열과 객체는 대량의 데이터를 쉽게 다루기 위해 사용한다. 그리고 이들을 쉽게 사용할 수 있는 이유는 크기가 동적이기 때문이다.
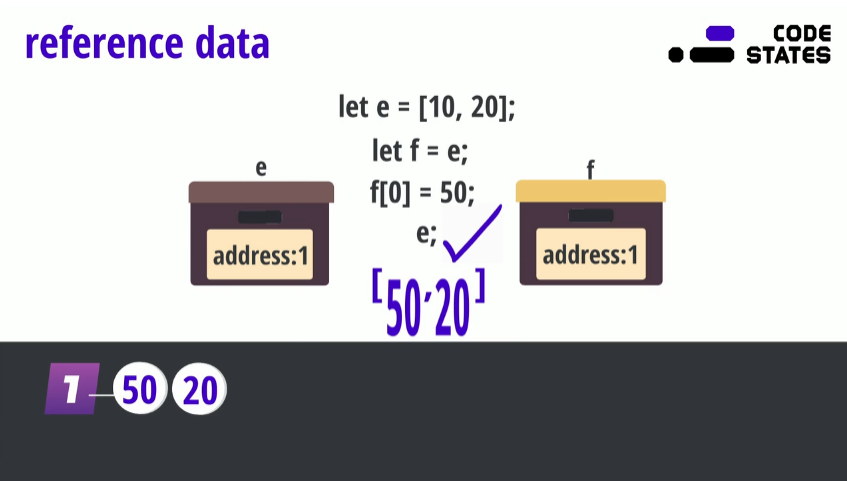
참조 타입을 복사하게 되면 스택 내부에 있는 주소를 복사한다. 복사한 데이터에서 값을 변경하게 된다면 주소 안에서 값을 변경하기 때문에 기존 데이터에도 영향이 미치게 된다. (mutable)
Uploaded by N2T