
알고리즘
알고리즘은 어떤 문제를 해결하기 위해 일련의 절차를 정의하고, 공식화한 형태로 표현한 일종의 문제 풀이 방법, 해(解)를 의미한다. 프로그래밍에서는 input 값을 통해 output 값을 얻기 위한 계산 과정을 의미하며, 정확하고 효율적으로 결과 값을 얻어야 할 때 사용된다. 하지만 단순히 일련의 절차를 정의하고 공식화 한다 해서 알고리즘이라 할 수 없고, 일정한 조건들을 만족해야 한다.
- 입력(Input) : 출력에 필요한 자료를 입력받을 수 있어야 한다. 단, 입력을 받지 않아도 되는 알고리즘도 존재한다.
- 출력(Output) : 실행이 되면 적어도 한 가지 이상의 결과를 반드시 출력해야 한다. 알고리즘의 종료와 같다 볼 수 있다.
- 유한성(Finiteness) : 유한한 명령어를 수행한 후 유한한 시간 내에 종료해야 한다. 반드시 종료되어야 한다는 말과 같으며, 출력과 연관성 있다.
- 명확성(Definiteness) : 각 단계는 단순하고 명확해야 하며, 모호해서는 안된다.
- 효율성(Efficiency) : 가능한 한 효율적이어야 한다. 명백히 실행 가능해야 하며, 시간 복잡도와 공간복잡도와 깊은 연관성이 있다.
알고리즘의 중요성
알고리즘은 프로그래밍 뿐만 아니라 일상생활에서도 다양한 문제를 해결하는 데에 활용할 수 있다. 좋은 알고리즘은 절차가 명확하게 표현되어 있고 효율적이므로 다양한 문제 해결 과정에서 나타나는 불필요한 작업들을 줄여줄 수 있다.
시간 복잡도 (Time Complexity)
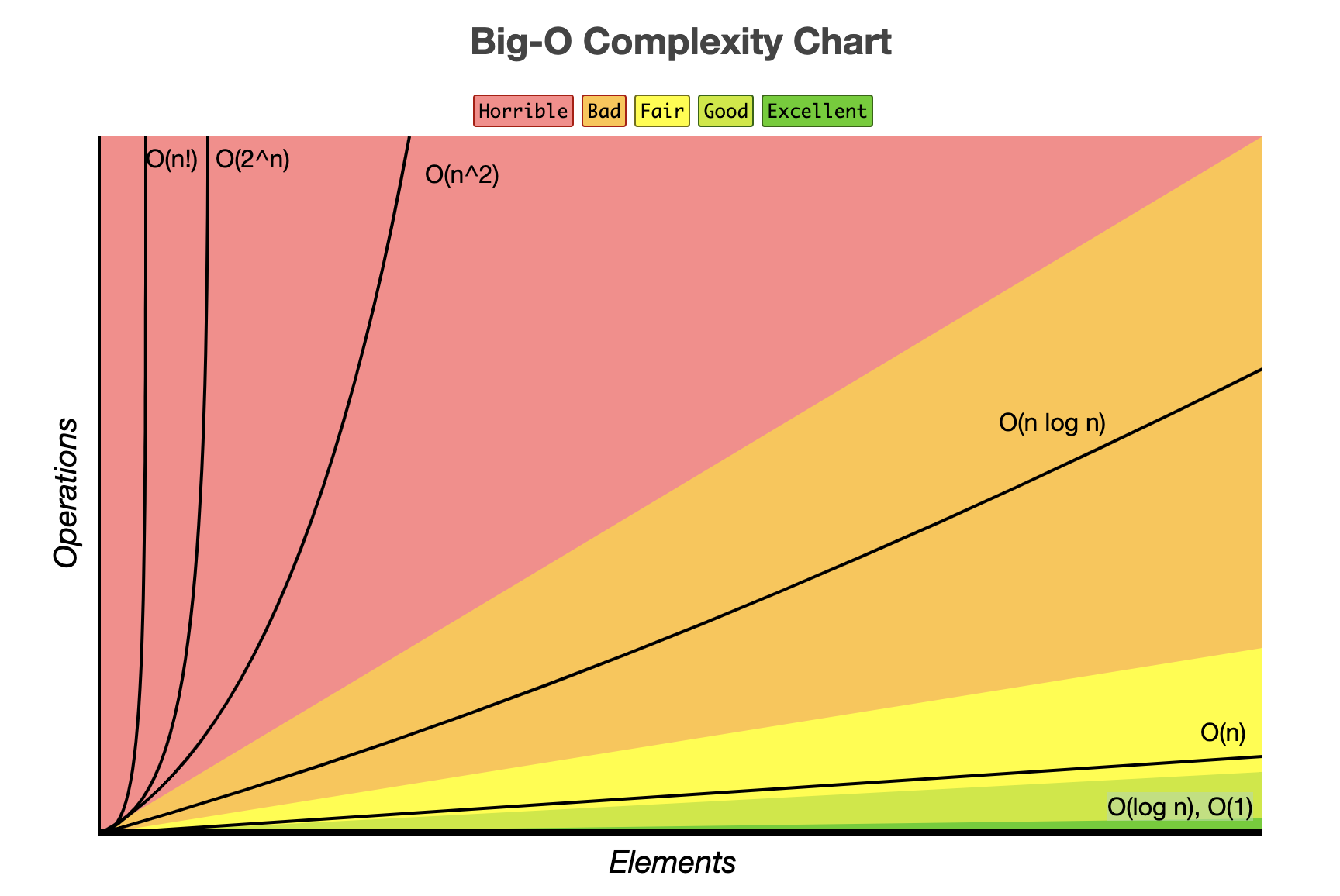
시간 복잡도는 입력값의 변화에 따라 연산 실행 시 연산 횟수에 비해 시간이 얼마나 걸리는지를 표현하는 지표이다. 효율적인 알고리즘을 구현한다는 것은 입력값이 커짐에 따라 증가하는 시간의 비율을 최소화한 알고리즘을 구성했다는 이야기이다.
Big-O 표기법
시간 복잡도를 표기하는 방법은 Big-O(빅-오), Big-Ω(빅-오메가), Big-θ(빅-세타)가 있는데, 이는 각각 최악, 최선, 중간(평균)의 경우에 대해 나타내는 방법이다. 이 중 Big-O 표기법이 가장 자주 사용되는데, 빅오 표기법은 최악의 경우를 고려하므로 프로그램이 실행되는 과정에서 소요되는 최악의 시간까지 고려할 수 있기 때문이다.
-
는 constant complexity라고 하며, 입력값이 증가하더라도 시간이 늘어나지 않는다. 즉, 입력값의 크기와 관계없이 즉시 출력값을 얻어낼 수 있다.
function O_1_algorithm(arr, index) { return arr[index]; } let arr = [1, 2, 3, 4, 5]; let index = 1; let result = O_1_algorithm(arr, index); console.log(result); // 2
-
은 linear complexity라고 부르며, 입력값이 증가함에 따라 시간 또한 같은 비율로 증가하는 것을 의미한다. 같은 비율로 증가한다면 몇 배(, 등)가 증가하던 간에 그 배율과 상관없이 으로 표기한다.
function O_n_algorithm(n) { for (let i = 0; i < n; i++) { // do something for 1 second } }
-
은 logarithmic complexity라고 부르며 Big-O표기법중 다음으로 빠른 시간 복잡도를 가진다. 대표적인 알고리즘으로는 BST(Binary Search Tree)가 있으며, 이는 원하는 값을 탐색할 때 노드를 이동할 때마다 경우의 수가 절반으로 줄어들기 때문에 탐색을 진행할수록 결과에 접근하는 시간이 점점 짧아진다.

-
은 quadratic complexity라고 부르며, 입력값이 증가함에 따라 시간이 n의 제곱수의 비율로 증가하는 것을 의미한다. 과 마찬가지로 , 의 경우라도 모두 로 표기한다.
function O_quadratic_algorithm(n) { for (let i = 0; i < n; i++) { for (let j = 0; j < n; j++) { // do something for 1 second } } }
-
은 exponential complexity라고 부르며 Big-O 표기법 중 가장 느린 시간 복잡도를 가진다. 입력값이 증가함에 따라 시간이 2의 n제곱만큼 증가하게 되며, 대표적으로는 피보나치 수열을 재귀로 구현하는 알고리즘이 있다.
function fibonacci(n) { if (n <= 1) { return 1; } return fibonacci(n - 1) + fibonacci(n - 2); }
데이터 크기에 따른 시간 복잡도
일반적으로 코딩 테스트 문제를 풀 때에는 정확한 값을 제한된 시간 내에 반환하는 프로그램을 작성해야 한다. 따라서 시간제한과 주어진 데이터 크기 제한에 따른 시간 복잡도를 어림잡아 예측해 보는 것은 중요하다. 입력 데이터에 시간 복잡도를 대입하면 대략적으로 해당 문제에서 어느정도의 시간 복잡도를 요구하는지 유추해볼 수 있다. 입력 데이터가 클 때는 이나 의 시간 복잡도를 예측해서 문제를 풀어야 하고, 주어진 데이터가 작다면 시간 복잡도보다는 문제의 풀이에 집중하는 것이 좋다.
| 데이터 크기 제한 | 예상되는시간 복잡도 |
| n ≤ 1,000,000 | or |
| n ≤ 10,000 | |
| n ≤ 500 | |
공간 복잡도(Space Complexity)
공간 복잡도는 알고리즘이 수행되는 데에 필요한 메모리의 총량을 의미한다. 즉, 프로그램이 필요로 하는 메모리 공간을 산출하는 것을 말한다.
프로그램은 고정적인 공간과 가변적인 공간을 함께 요구하는데, 고정적인 공간은 처리할 데이터의 양과 무관하게 항상 요구되는 공간으로 프로그램의 성능에 큰 영향을 주지 않는다. 하지만 가변적인 공간은 처리할 데이터의 양에 따라 다르게 요구되는 공간으로서 프로그램의 성능에 큰 영향을 주기 때문에 가변적인 공간에 집중할 필요가 있다.
공간 복잡도 계산은 시간 복잡도 계산과 비슷하게 빅오(Big-O) 표기법으로 표현한다.
function factorial(n) {
if(n === 1) {
return n;
}
return n*factorial(n-1);
}위의 함수는 재귀함수이기 때문에 변수 n이 n개 만들어지게 되며 호출할 경우 n부터 1까지 스택에 쌓이게 되므로 해당 함수의 공간 복잡도는 이라 볼 수 있다.
공간 복잡도의 중요성
보통 시간 복잡도에 비해 공간 복잡도는 중요성이 떨어진다. 시간이 적으면서 메모리가 지수적으로 증가하는 경우를 보기 드물며, 시간 내에 발생하는 메모리 문제들은 보통 알고리즘을 구현할 때에 발생하는 문제이기 때문이다.
하지만 동적 계획법(Dynamic Programming)과 같은 알고리즘이나 하드웨어 환경이 매우 한정된 경우의 상황에서는 공간 복잡도를 중요하게 본다. 동적 계획법은 알고리즘 자체가 구현 시에 메모리를 많이 요구하기 때문에 입력값의 범위가 넓어지면 사용하지 못하는 경우도 많고, 하드웨어 환경이 매우 한정된 경우(임베디드, 펌웨어 등)라면 가용 메모리가 제한되기 때문이다.
Algorithm의 유형
Greedy Algorithm
Greedy Algorithm(탐욕 알고리즘)은 말 그대로 선택의 순간마다 당장 눈앞에 보이는 최적의 상황만을 쫓아 최종적인 해답에 도달하는 방법이다. 탐욕 알고리즘으로 문제를 해결하는 방법은 다음과 같이 단계적으로 구분할 수 있다.
Greedy Algorithm 문제 해결 단계
- 선택 절차(Selection Procedure): 현재 상태에서의 최적의 해답을 선택한다.
- 적절성 검사(Feasibility Check): 선택된 해가 문제의 조건을 만족하는지 검사한다.
- 해답 검사(Solution Check): 원래의 문제가 해결되었는지 검사하고, 해결되지 않았다면 선택 절차로 돌아가 위의 과정을 반복한다.
탐욕 알고리즘은 문제를 해결하는 과정에서 매 순간, 최적이라 생각되는 해답(locally optimal solution)을 찾으며, 이를 토대로 최종 문제의 해답(globally optimal solution)에 도달하는 문제 해결 방식이다.
탐욕 알고리즘의 특징
- 탐욕적 선택 속성(Greedy Choice Property) : 앞의 선택이 이후의 선택에 영향을 주지 않는다.
- 최적 부분 구조(Optimal Substructure) : 문제에 대한 최종 해결 방법은 부분 문제에 대한 최적 문제 해결 방법으로 구성된다.
탐욕 알고리즘은 위 두 조건을 만족하는 특정한 상황이 아니라면 최적의 해를 보장하지 못한다. 단, 최적의 결과를 도출하는 것과 달리 어느정도 최적에 근사한 값을 빠르게 도출할 수 있는 장점이 있기 때문에 근사 알고리즘으로 사용할 수 있다.
Dynamic Programming(DP, 동적 계획법)
동적 계획법(DP)은 탐욕 알고리즘과 같이 작은 문제에서 출발한다는 점은 같지만, 매 순간 최적의 선택을 찾는 탐욕 알고리즘과 달리 DP는 모든 경우의 수를 조합해 최적의 해법을 찾는다.
즉, 주어진 문제를 여러 개의 작은 하위 문제로 나누어 풀고 하위 문제들의 해결 방법을 결합해 최종 문제를 해결한다. 하위 문제를 계산한 뒤 그 해결책을 저장하고, 나중에 동일한 하위 문제를 만날 경우 저장된 해결책을 적용해 계산 횟수를 줄인다. 다시 말해 하나의 문제는 단 한 번만 풀도록 하는 알고리즘이다.
동적 계획법의 특징
DP는 다음 두 가정이 만족하는 조건에서 사용할 수 있다.
- Overlapping Sub-problems : 큰 문제를 작은 문제로 나눌 수 있고, 이 작은 문제가 중복해서 발견된다.
- Optimal Substructure : 작은 문제에서 구한 정답은 그것을 포함하는 큰 문제에서도 같다. 즉, 작은 문제에서 구한 정답을 큰 문제에서도 사용할 수 있다.
Algorithm 구현의 기초
알고리즘 문제를 푼다는 것은 내가 생각한 문제 해결 과정을 컴퓨팅 사고로 변환하여 코드로 구현한다는 것과 같다. 다시 말해 내가 생각한 로직으로 끝나는 것이 아닌 코드로 구현하는 것까지 포함한다는 뜻이다. 머리로 이해하고 있어도 코드로 작성하지 않는다면 정답이 될 수 없다.
선택한 프로그래밍 언어의 문법을 정확히 알고 있고, 문제의 조건에 전부 부합하는 코드를 실수 없이 빠르게 작성하는 것을 목표로 두는 것을 구현 문제, 구현 유형이라 통칭할 수 있다. 보통 이런 문제들은 구현하는 것 자체를 굉장히 까다롭게 만들기 때문에 깊은 집중력과 끈기가 필요하다.
구현 능력을 보는 대표적인 사례에는 완전 탐색과 시뮬레이션이 있다.
완전 탐색
완전 탐색은 단순히 모든 경우의 수를 탐색하는 모든 경우를 통칭한다. 모든 문제는 완전 탐색으로 풀 수 있다. 이 방법은 단순무식해도 답이 무조건 있다는 강력함이 있지만, 문제 해결이 아닌 효율성을 만족해야 하는 문제라면 최적의 해결법을 달성할 수 없는 경우가 발생할 수 있다. 따라서 완전 탐색은 문제를 풀 수 있는 가능한 모든 방법을 고려한 후 효율적으로 동작하는 알고리즘이 완전 탐색 밖에 없다고 판단될 때 적용할 수 있다.
완전 탐색을 하는 방법에는 Brute Force(조건/반복을 사용하여 해결), 재귀, 순열, DFS/BFS 등 여러 가지가 있다.
Brute Force
Brute Force Algorithm은 무차별 대입 방법을 나타내는 알고리즘이다. 순수한 컴퓨팅 성능에 의존해 모든 가능성을 시도해 문제를 해결하는 방법이며, 이 또한 완전 탐색이기 때문에 최적의 솔루션이 아니라는 것을 의미한다. 시간 복잡도와 공간 복잡도를 고려하지 않더라도 솔루션 자체를 찾으려는 방법이기 때문에, 데이터의 범위가 커질수록 상당히 비효율적이다.
Brute Force Algorithm은 크게 프로세스 속도를 높이는데 사용할 수 있는 다른 알고리즘이 없거나 문제를 해결하는 여러 솔루션이 있고 각 솔루션을 확인할 때 사용된다.
- 예시
자연수 1부터 100을 요소로 무작위로 정렬된 배열이 있다. 입력 값으로 배열과 자연수 하나가 들어왔을 때, 해당 자연수 이후에 있는 요소들을 모두 더한 결과값을 반환해야 한다.
const solution = (arr, num) => { let key = 101; let result = 0; for (let i = 0; i <= arr.length; i++){ const item = arr[i]; if(item === num) key = i; if(key < i) result += item; } return result; }
시뮬레이션
시뮬레이션은 모든 과정과 조건이 제시되어 그 과정을 거친 결과가 무엇인지 확인하는 유형이다. 보통 문제에서 설명해 준 로직 그대로 작성하면 되기 때문에 해결 자체를 떠올리는 것은 쉬울 수 있지만 길고 자세한 경우 코드로 옮기는 작업이 까다로울 수 있다. 문제에 대한 이해를 바탕으로 제시하는 조건을 하나도 빠짐없이 처리해야 정답을 받을 수 있기 때문이다.
시뮬레이션 예시
무엇을 위한 조직인지는 모르겠지만, 비밀스러운 비밀 조직 '시크릿 에이전시'는 소통의 흔적을 남기지 않기 위해 3 일에 한 번씩 사라지는 메신저 앱을 사용했습니다. 그러나 내부 스파이의 대화 유출로 인해 대화를 할 때 조건을 여러 개 붙이기로 했습니다. 해당 조건은 이렇습니다.
- 캐릭터는 아이디, 닉네임, 소속이 영문으로 담긴 배열로 구분합니다.
- 소속은 'true', 'false', 'null' 중 하나입니다.
- 소속이 셋 중 하나가 아니라면 아이디, 닉네임, 소속, 대화 내용의 문자열을 전부 X로 바꿉니다.
- 아이디와 닉네임은, 길이를 2진수로 바꾼 뒤, 바뀐 숫자를 더합니다.
- 캐릭터와 대화 내용을 구분할 땐
공백:공백으로 구분합니다 ⇒ ['Blue', 'Green', 'null'] : hello.
- 띄어쓰기 포함, 대화 내용이 10 글자가 넘을 때, 내용에
.,-+이 있다면 삭제합니다.
- 띄어쓰기 포함, 대화 내용이 10 글자가 넘지 않을 때, 내용에
.,-+@#$%^&*?!이 있다면 삭제합니다.
- 띄어쓰기를 기준으로 문자열을 반전합니다: 'abc' -> 'cba'
- 띄어쓰기를 기준으로 소문자와 대문자를 반전합니다: 'Abc' -> 'aBC'
시크릿 에이전시의 바뀌기 전 대화를 받아, 해당 조건들을 전부 수렴하여 수정한 대화를 객체에 키와 값으로 담아 반환하세요. 같은 캐릭터가 두 번 말했다면, 공백을 한 칸 둔 채로 대화 내용에 추가되어야 합니다. 대화는 문자열로 제공되며, 하이픈
-으로 구분됩니다.문자열은 전부 싱글 쿼터로 제공되며, 전체를 감싸는 문자열은 더블 쿼터로 제공됩니다.
예: "['Blue', 'Green', 'null'] : 'hello. im G.' - ['Black', 'red', 'true']: '? what? who are you?'"
"['Blue', 'Green', 'null'] : 'hello. im G.' - ['Black', 'red', 'true']: '? what? who are you?'"입력값으로 받은 문자열을 각 캐릭터와 대화에 맞게 문자열로 파싱을 하고, 파싱한 문자열을 상대로 캐릭터와 대화를 구분한다.- 첫 번째 파싱은
-을 기준으로 두 부분으로 나눈다.['Blue', 'Green', 'null'] : 'hello. im G.'['Black', 'red', 'true']: '? what? who are you?'
- 두 번째 파싱은
:을 기준으로 배열과 문자열로 나눈다.['Blue', 'Green', 'null']'hello. im G.'
- 첫 번째 파싱은
- 배열과 문자열을 사용해, 조건에 맞게 변형한다.
- 소속이 셋 중 하나인지 판별한다.
['Blue', 'Green', 'null']아이디와 닉네임의 길이를 2진수로 바꾼 뒤, 숫자를 더한다. ⇒[1, 2, 'null']
'hello. im G.'10 글자가 넘기 때문에,.,-+@#$%^&*를 삭제한다. ⇒'hello im G'
'hello im G'띄어쓰기를 기준으로 문자열을 반전한다. ⇒'olleh mi G'
'olleh mi G'소문자와 대문자를 반전한다. ⇒'OLLEH MI g'
- 변형한 배열과 문자열을 키와 값으로 받아 객체에 넣는다.
{ "[1, 2, 'null']": 'OLLEH MI g' }
Algorithm with Math
최근 코딩 테스트에서 출제되는 문제는 특정 방법을 사용해 문제를 푸는 것을 상정하는 경우가 많다. 이런 문제는 수학적 사고 능력, 다시 말해 컴퓨팅 사고가 가능한 것인지 확인하기 때문에 수학적 사고를 통해 컴퓨팅 사고를 할 수 있어야 한다.
순열
순열(順列, permutation)은 서로 다른 개의 원소를 가지는 어떤 집합에서 중복없이 순서에 상관있게 개의 원소를 선택하거나 나열하는 것이며, 이는 개의 원소로 이루어진 집합에서 개의 원소로 이루어진 부분집합을 만드는 것과 같다.
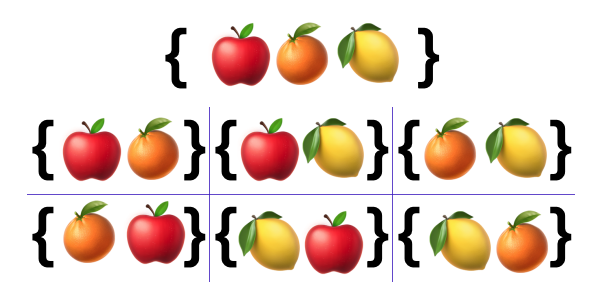
사과와 오렌지, 레몬으로 이루어진 집합이 있다. 만약 3가지 과일 중 2가지의 과일을 중복 없이, 순서에 상관있게 부분 집합을 만든다면 총 6개의 부분집합이 나올 수 있을 것이다. 단순히 집합에 요소가 존재하는 것만 따지는 것이 아닌 순서까지 따지기 때문이다.
순열의 식
순열은 일반화 과정을 거쳐 Permutation의 약자 로 표현한다. 수식의 각 의미는 아래와 같다. 순열은 중복을 허용하지 않기 때문에, 반드기 을 만족해야 한다.
- : 원소의 총 갯수
- : 부분 집합으로 만들 요소의 갯수
조합
조합(組合, combination)은 서로 다른 개의 원소를 가지는 어떤 집합에서 중복 없이 순서에 상관없게 개의 원소를 선택하는 것이며, 이는 순열과 마찬가지로 개의 원소로 이루어진 집합에서 개의 원소로 이루어진 부분집합을 만드는 것과 같다.

아까처럼 세 과일 중 2가지 과일을 중복 없이, 순서에 상관없는 부분집합을 만든다면 총 3개의 부분집합이 나올 수 있다. 조합은 순서에 상관없이 원소를 선택해 부분집합을 만드는 것이기 때문에, 요소의 순서가 중복되지 않아도 하나의 경우의 수로 치는 것이다.
조합의 식
조합은 일반화 과정을 거쳐, Combination의 약자 로 표현한다. 수식의 각 의미는 아래와 같다. 순열은 중복을 허용하지 않기 때문에, 반드기 을 만족해야 한다.
GCD와 LCM(최대공약수, 최소공배수)
최대공약수(Greatest Common Divisor, GCD)는 두 수 이상의 여러 공약수에서 최대인 수를 의미하며, 최소공배수(Lowest Common Multiple, LCM)는 두 수 이상의 여러 공배수 중 최소인 수를 가리킨다.
GCD와 LCM을 구하는 기본적인 방법 : 공약수로 나누어보기
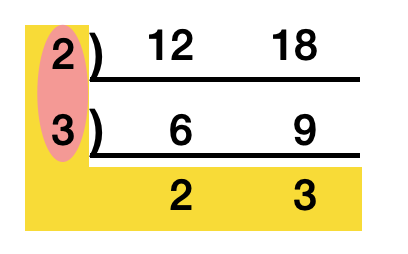
가장 기본적인 방법은 공약수로 더이상 나눌 수 없는 수까지 나누는 것이다. 나누고 나서는 나눌 때 사용한 약수를 모두 곱하면 최대공약수, 최대공약수에 나눌 수 없는 수까지 모두 곱하면 최대공배수가 된다.
GCD와 LCM을 구하는 유클리드 호제법
유클리드 호제법은 최대공약수와 관련이 깊은 공식이다. 2개의 자연수 와 가 있을 때, 를 로 나눈 나머지를 이라 하면 와 의 최대공약수는 와 의 최대공약수와 같다는 이론이다. 이러한 성질에 따라 를 로 나눈 나머지 을 구하고, 다시 을 로 나누는 과정을 반복해 나머지가 0이 되었을 때 나누는 수가 와 가 최대공약수임을 알 수 있다.
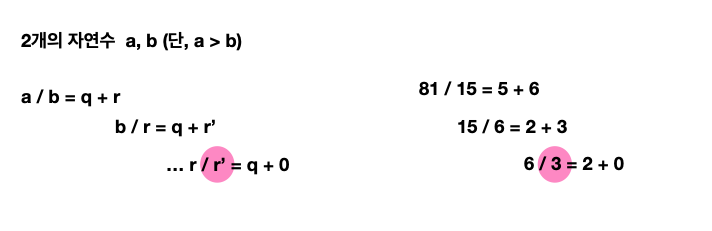
위의 사진을 보고 이해해보자. 와 를 나누었을 때 (몫, Quontient)와 (나머지, Rest)이 나온다. 여기서 다시 를 로 나눕니다. 그러면 다시 몫인 와 나머지인 가 나올 것이고, 을 다시 와 나누게 되면 언젠가 몫인 와 나머지인 이 0이 되는 상황이 도출된다. 이 때 나누는 수인 가 바로 최대공약수라는 의미이다.
위의 공식을 토대로 최대공약수와 최소공배수를 구하는 공식을 함수화 하면 아래와 같다.
const getGCD = (num1, num2) => (num2 > 0 ? getGCD(num2, num1 % num2) : num1);
const getLCM = (a, b) => a * b / getGCD(a, b);멱집합
집합 {1, 2, 3}의 모든 부분집합을 통틀어 멱집합이라 한다. 모든 부분집합을 나열하는 방법은 다음과 같이 몇 단계로 구분할 수 있으며, 부분집합을 나열하는 방법에서 가장 앞 원소(혹은 임의의 집합 원소)가 있는지, 없는지에 따라 단계를 나누는 기준을 결정한다.
- Step A: 1을 제외한 {2, 3}의 부분집합을 나열한다.
- Step B: 2를 제외한 {3}의 부분집합을 나열한다.
- Step C: 3을 제외한 {}의 부분집합을 나열한다. → {}
- Step C: {}의 모든 부분집합에 {3}을 추가한 집합들을 나열한다. → {3}
- Step B: {3}의 모든 부분집합에 {2}를 추가한 집합들을 나열한다.
- Step C: {3}의 모든 부분집합에 {2}를 추가한 집합들을 나열하려면, {}의 모든 부분집합에 {2}를 추가한 집합들을 나열한 다음 {}의 모든 부분집합에 {2, 3}을 추가한 집합들을 나열한다. → {2}, {2, 3}
- Step B: 2를 제외한 {3}의 부분집합을 나열한다.
- Step A: {2, 3}의 모든 부분집합에 {1}을 추가한 집합들을 나열한다.
- Step B: {2, 3}의 모든 부분집합에 {1}을 추가한 집합들을 나열하려면, {3}의 모든 부분집합에 {1}을 추가한 집합들을 나열한 다음 {3}의 모든 부분집합에 {1, 2}를 추가한 집합들을 나열한다.
- Step C: {3}의 모든 부분집합에 {1}을 추가한 집합을 나열하려면, {}의 모든 부분집합에 {1}을 추가한 집합들을 나열한 다음 {}의 모든 부분집합에 {1, 3}을 추가한 집합들을 나열한다. → {1}, {1, 3}
- Step C: {3}의 모든 부분집합에 {1, 2}를 추가한 집합을 나열하려면, {}의 모든 부분집합에 {1, 2}를 추가한 집합들을 나열한 다음 {}의 모든 부분집합에 {1, 2, 3}을 추가한 집합들을 나열한다. → {1, 2}, {1, 2, 3}
- Step B: {2, 3}의 모든 부분집합에 {1}을 추가한 집합들을 나열하려면, {3}의 모든 부분집합에 {1}을 추가한 집합들을 나열한 다음 {3}의 모든 부분집합에 {1, 2}를 추가한 집합들을 나열한다.
원소가 있는지, 없는지 2가지 경우를 고려하기 때문에 집합의 요소가 n 개일 때 모든 부분집합의 개수는 2n개 이다. 예를 들어 집합의 원소가 4개라면 모든 부분집합의 개수는 24, 집합의 원소가 5개라면 25가 됩니다. 간단히 {1, 2, 3}의 모든 부분집합을 구하는 단계는 다소 복잡해 보일 수 있지만, 트리구조와 비슷한 형태임을 알 수 있다.
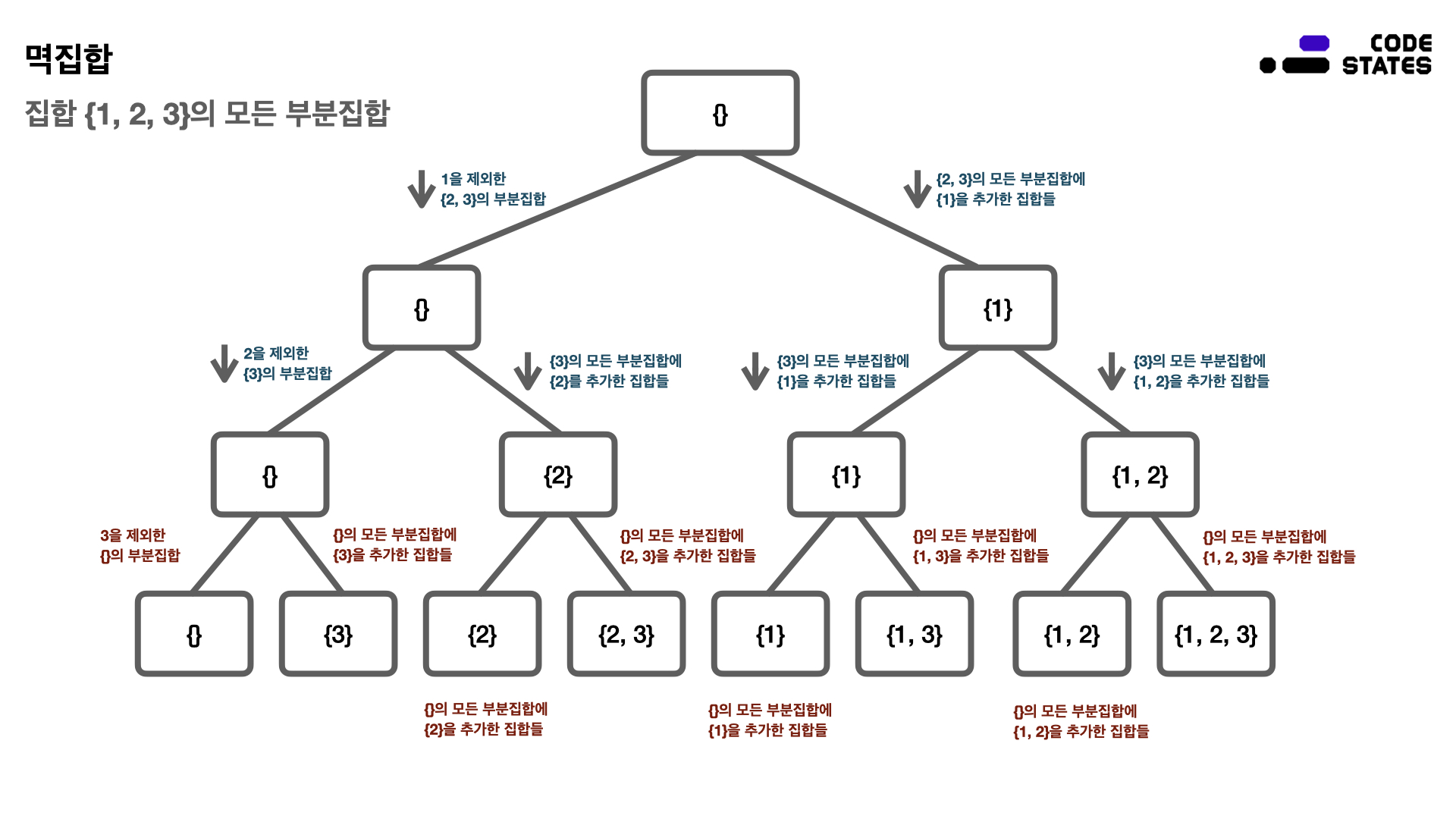
멱집합을 구하는 방법에서 각 단계를 유심히 살펴보면, 순환 구조를 띠는 것을 확인할 수 있는데, 순환구조는 임의의 원소를 제외하면서 집합을 작은 단위로 줄여나가는 방법입니다. 따라서, 문제를 작은 단위로 줄여나가는 재귀를 응용할 수 있다. 문제가 가장 작은 단위로 줄어들고, 함수가 리턴될 때 카운트를 올리는 방식으로 멱집합의 개수를 구할 수 있다.
Uploaded by N2T